A fully customizable course for the digital LSAT
We combine cutting-edge technology with personal coaching to help you master the test
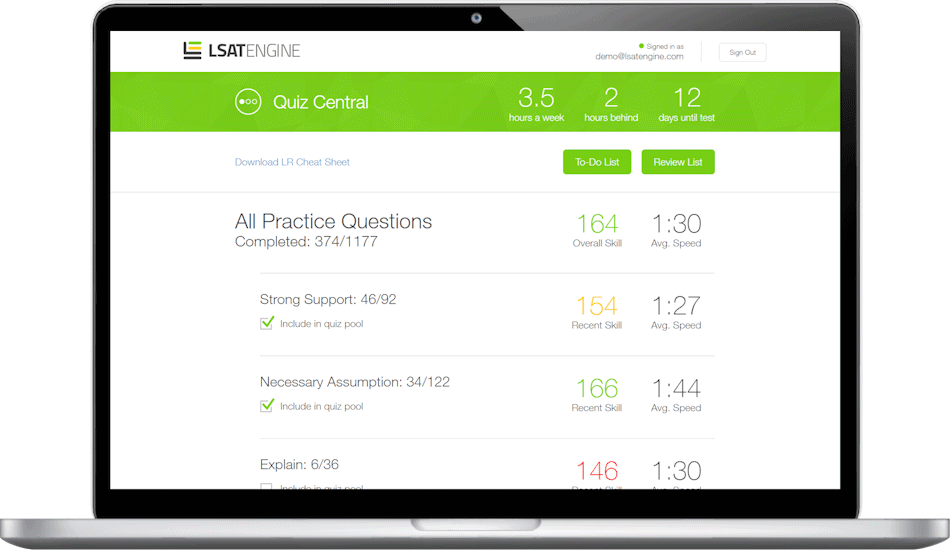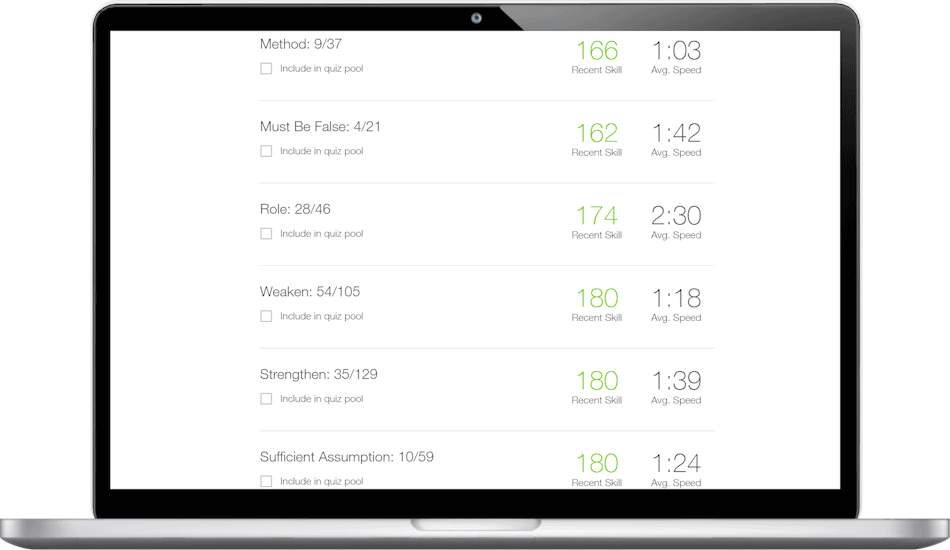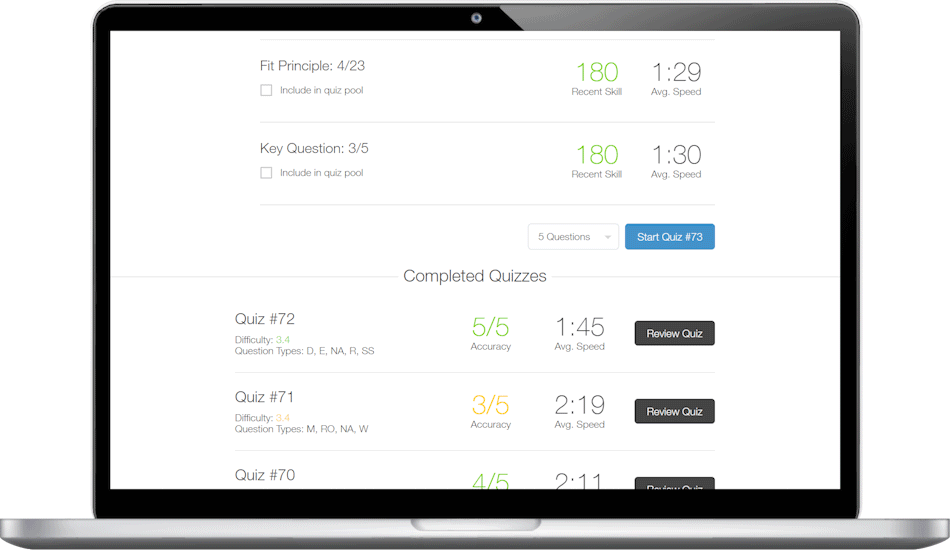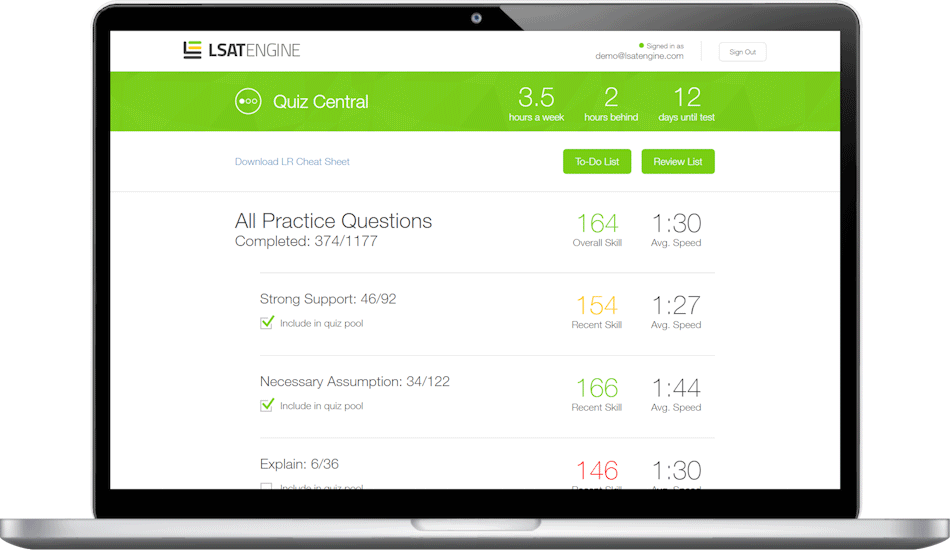
We combine cutting-edge technology with personal coaching to help you master the test

"I had tried 4 of the major LSAT prep courses before I finally stumbled upon LSAT Engine. When I saw that LSAT Engine offered a fee waiver program I immediately applied. I was shortly after accepted and given full access to an immense amount of LSAT content and resources. Previous to LSAT Engine, I had established a good foundation where I was able to score consistently in the low 160s but I was struggling to increase past that point. I began using LSAT Engine every day, whether it was the super helpful quiz feature (in which you can drill specific question types) or the thorough problem explanation videos offered for every single question! My score began to gradually increase week-by-week and eventually, I found myself scoring in the 170s! On test day I scored a 172 and quite frankly, there is no way I could have done that without the help of Josh and all of the amazing people at LSAT Engine. I recommend LSAT Engine to everyone that I know who is studying for the LSAT and attribute a lot of my success to the effective curriculum and the question-type specific quiz feature."

"I would recommend LSAT Engine without hesitation, for five reasons: 1) the LSAT exam is now administered on a tablet, and you should get into the habit of operating in that capacity as soon as possible. In that regard, LSAT Engine provides excellent preparation; 2) the video explanations are comprehensive and leave little, if anything, to question; 3) the lessons are fantastic and rooted in a logic that is easy to grasp and retain; 4) the price point is extremely affordable. I would argue that what Justin is doing with his LSAT Engine program is helping to level the playing field between the have and have-nots when it comes to law school admissions; and 5) JUSTIN! He was always available when I needed to pull him in on things for which I just could not crack the code. This program is comprehensive and got me from ground 0 to an 11-point increase over the course of three of the worst months of my life (not-LSAT related). I took the LSAT again one month later and increased my score another 2 points, for a 13-point increase in total (and I could have continued!!). The absolute most impactful thing I can say is that LSAT Engine helped me get the score that I needed to get a scholarship to my top choice school. The investment of $699 (and my time) yielded a 10,000%+ return for me (based on real numbers!). Thank you Justin!!"

"I first heard of LSAT Engine at a Black Pre-Law Society Event, during which a tutor demonstrated a logic game. I instantly appreciated how the tutor explained the game and gave a preview of what to expect on the LSAT. Studying for the LSAT can be like learning a new way of thinking, so it is nice to have a program that does a great job breaking down difficult concepts. I also loved the flexibility because I studied while I was in undergrad and working part-time. Additionally, I think LSAT Engine's study schedule gave me a great foundation in self-discipline and time management that I still use in law school."

"I cannot recommend LSAT Engine highly enough. No unnecessary jargon. More practice questions, sections, and tests than you will need with video explanations for each question. The provided study schedule offers a tailored pace to build vital understanding of the test as the LSAT is 100% learnable. Consistent practice and sage advice from Justin and LSAT Engine’s individual performance counselors helped take me from a diagnostic score of 158 in March to a 180 on the August 2020 LSAT-Flex.
For someone serious about performing well, LSAT Engine is the place to get the most bang for your buck and make that goal score possible!"

"LSAT Engine is great. Justin is super helpful and available. The program is really dynamic in that it helps YOU improve on what YOU'RE struggling with. LSAT Engine is hands down the most efficient way to study for the LSAT."

"Like most undergrads planning on going to law school, thinking about the LSAT always sent me into a bit of a panic in my first few years of college. I had heard a lot of conflicting advice about how best to study and didn’t want to leave anything to chance. When I found out about LSAT Engine, with its online model and amazing success rate, it seemed above and beyond any other LSAT prep option. Within days of enrolling with LSAT Engine, I knew I had made the right choice.
I’m the kind of person who gets motivation through competition and LSAT Engine gave me all the tools to focus on reaching new personal records and bests. The schedule function gave me a really accurate timetable of what needed to be accomplished each week and I used the time tracker to ensure I was staying consistent with my study schedule. The videos were always clear and thorough. I never finished a video feeling confused and Justin’s methods for tackling each section proved extremely effective. I raised my score by 10 points just between the base test and my first practice test after studying the curriculum. From there, I used the practice tests and personalized quiz functions to hone my skills and was able to go up another 7 points, ultimately ending up with a 174 on the official LSAT. While some of my friends who studied from books and other LSAT courses had to retake their LSAT, I only had to take it once because LSAT Engine was just that effective. I now recommend it to anyone who asks about LSAT prep, as I believe it provides the best strategies for tackling the test as well as the best data for holding each student accountable for their study schedule. The guidance provided by Justin and the LSAT Engine team are genuinely unmatched in the field and I’m confident you can’t go wrong with LSAT Engine!"

"When I first had this course recommended to me by a friend, I had no idea what to expect. It was affordable, entirely online, but I had no idea if it would help me. I had friends taking courses with other prep companies who felt they weren't improving their scores much at all, and I worried about how much this would help me. But self-study wasn't getting me very far, and I thought it would be worth taking a chance. I'm glad I did, because I went from getting a 160 on practice tests to consistently scoring in the mid-170s, and getting a 172 on the official LSAT. Now I'm headed to Harvard Law, and I couldn't be more thankful for the help I got from LSAT Engine.
From start to finish, the study regiment set up by LSAT Engine really helped me focus on the areas I needed to work on most, and improve my score by more than 10 points by the time of the LSAT itself. I was able to take the course at my own pace, and Justin was there to help me each step of the way, fielding any questions I had and helping me stay on track to improve my score. The website was easy to navigate, and I had every option I could need (from video explanations to a variety of practice questions) at the tip of my fingers at all times.
I can't rate this course and the help Justin provided me personally highly enough. I definitely recommend that anyone who wants to seriously improve their LSAT score look into this option, which is not only more affordable than most other programs, but is also worth its price many times over. When every point on the LSAT can mean potential future earnings of thousands upon thousands of dollars, or even thousands upon thousands of dollars of scholarships, using an affordable and extremely effective course like this to improve your score should be a no-brainer."

"I would liken Justin to a well trained surgeon, taking each part of a student's preparation into account when setting priorities. He was the quintessential tutor, directing not only my technical approach, but also my psychological approach for the LSAT. There's a certain mentality that must be fostered over months of preparation that contributes greatly to your success on this test. Justin is the best in the business at helping you achieve what you thought you couldn't."

"LSAT Engine was truly the perfect test prep for me and I would recommend it to anyone in the market for an LSAT study program. Justin is an incredible teacher and it was evident that he wanted me to succeed. Not only did he explain concepts clearly and efficiently in his videos, but he was always available to answer questions and would provide me with extra study materials if I asked.
Studying for the LSAT can be a daunting task, especially when you are trying to balance studying with school/work/etc. Yet, LSAT Engine helps you juggle all of these competing responsibilities by giving you a study schedule that is specifically tailored to you. I loved that I could work at my own pace and yet still feel as though I was completely on track. Because of LSAT Engine and Justin, I was able reach my target score and I could not be more grateful."

"Justin's attention to detail is unmatched, and the tailored nature of his program allows each student to hone in on areas of improvement and feel confident heading into test day. He has the quality that we wish for in all our teachers -- a unique ability to take a complex topic and break it into smaller, understandable parts. His optimism is relentless and contagious, and I'm glad that via LSAT Engine, more students will have the privilege of benefiting from his wisdom and experience."

"LSAT Engine is, without a doubt, the best study program I have found. After two LSATs and trying four different study programs, I finally found the perfect one for me. The way the program adapts to what you need the most help in really allowed me to focus on my problem areas and improve overall. Both Justin and Josh were always available and happy to help me with whatever I needed. Through personal phone calls and emails, it was clear that they both really want us to succeed. The videos were simple enough to not be overwhelming, but detailed enough to truly get the point across. Because of LSAT Engine, my score went up by 9 points and I can now go to the schools that I want."

"When I met Josh Lord playing pick-up basketball, LSAT Engine was months away from being launched. I am so glad I waited and took a chance on the brand new program. Not only is LSAT Engine much more affordable than traditional prep courses, it is also far ahead of the curve in terms of allowing independent people to study anywhere at any time. Along with this flexibility, LSAT Engine provided a thorough breakdown of the reasoning skills necessary not only to succeed on the LSAT but also in law school and beyond. I was impressed by Justin's commitment to the program. His frequent check-ins helped me get through the rough patches of the study grind. The practice tests he organized were crucial in boosting my confidence on test day. Thanks to Josh and Justin, I reached the 92nd percentile of LSAT scores and have received generous scholarship offers from law schools."

"When I set out to study for the LSAT, I knew I needed to study hard. At the same time, I wanted to make sure I was spending my time productively with a course that would reinforce my stronger areas while strengthening the sections I was less comfortable with. LSAT Engine was the perfect fit. With seemingly unlimited practice questions, sections, and full LSAT exams, plus full video explanations for every question, this course changed the game for me. I took the September 2019 LSAT, which was the first fully digital exam. LSAT Engine very promptly updated their course to match the exact format of the digital LSAT, which allowed me to get comfortable with the medium I would be taking the test in. I started the course with an initial score of 149, and made a 163 on the actual LSAT, which put me exactly where I wanted to be as far as law school applications. This course has paid for itself more than tenfold in scholarship offers I have since received, and I truly cannot recommend LSAT Engine enough!"

"Using LSAT Engine was one of the best decisions I ever made. I recommend LSAT Engine to all my friends because it made a huge difference in my test preparation journey. In fact, LSAT Engine was recommended to me by another friend who also saw amazing results. Justin and other LSAT Engine staff are very helpful and accessible and took the time to ensure that their program worked for me. LSAT Engine can personalize your study schedule to fit your strengths and weaknesses, and its format is identical to the official online version of the LSAT. It has a library of thousands of questions and helpful videos explaining virtually every single one. There is truly nothing else like it in the test preparation industry. I spent a few months relying exclusively on LSAT Engine and improved by 8 points. I even had a couple of perfect tests in the leadup to my final testing day. Thanks to LSAT Engine, I am now entering the law school application process confident that my LSAT score will be a great asset to my candidacy."

"LSAT Engine is an incredible program and I would recommend it to anyone looking to study for the LSAT. I was the Vice President and then the President of Phi Alpha Delta at the University of the Pacific. I have sat through a variety of LSAT webinars from various companies. I can undoubtedly say LSAT Engine always stood out and was by far our most desired and anticipated webinar. Justin does an excellent job making the material interesting and engaging. His explanations are clear and make the material easy to digest. When it came time to pick a course I knew LSAT Engine was the perfect fit for me. The program has given me confidence in my knowledge and abilities.
The website is easy to access. There is a schedule to keep you on track and honestly accountable. The videos are clear and I’m never left with any questions. Both Justin and Josh are excellent resources and have always been willing to help. The hands on nature and personal touches of their program is what makes their company so special. I could not be happier with my decision to choose LSAT Engine and I highly recommend it to anyone interested in taking the LSAT. Great job Josh and Justin."

"I performed well for my LSAT goals (164 / 88th percentile, up from a 155 in a previous cycle.) Justin’s lectures are concise and practical, and the guidance on study schedules made a huge difference in my approach. Because LSAT Engine quizzes adapted to my strengths and weaknesses, I maximized my study time to focus on areas that needed improvement without losing ground on my best sections. I worked and attended school full-time, so squeezing the most out of 2 hours a day was pivotal in my test score. I’m now in my 2nd semester at Georgia State University’s College of Law, and I’m grateful for LSAT Engine helping me to get here."

"LSAT Engine provided me with resources tailored to my needs while studying for the highly anticipated LSAT. Having a personalized system combined with experts who were easy to contact from across the country helped me to have a successful LSAT experience. I feel confident that studying with LSAT Engine is helpful to people of all educational backgrounds, and creates a better chance of a successful LSAT for all."

"For someone who speaks English as a second language, and someone who found it extremely mentally draining to study for the LSAT, LSAT Engine created the perfect environment for me to prepare for the test. This is because LSAT Engine made the material that I needed to practice and tracking my progress ready to hand. In less than four months of proper studying, I was able to increase my score by 10 points from a 147 to a 157. I am very pleased that I will be attending USD School of Law in fall 2021. My goal to be someone who fights for humans’ rights through the legal system feels so much closer to reach, and this was made possible through LSAT Engine."

"My Pre-Law advisor introduced LSAT Engine to me after I didn’t have a great experience with a prior LSAT prep course. Once I signed up, LSAT Engine personally reached out to me to help me craft a personal study timeline where I could be in control of my LSAT studying. Additionally, LSAT Engine offered resources such as practice problems, tutorial videos, and personal online assistance if I needed someone to talk me through a tough question. Simply, LSAT Engine was everything I could have hoped for and wanted as I prepared for the LSAT and would recommend this LSAT prep course to anyone looking for a personalized study course that focuses on your individual strengths and weaknesses. Thank you, LSAT Engine, for helping me succeed, and attend Baylor Law School!"

"After having moderate success with a major test prep organization, I worked with Justin and my score almost immediately improved. He has an incredibly deep understanding of the test. He explained what types of questions I was likely to see and what strategies I should employ depending on the question I was facing. My score dramatically improved because of Justin's incredible teaching."

"While I felt that the instructors at TestMasters were trained to explain problems in one or two different ways max, Justin had the amazing ability to explain a logical reasoning problem to me in four different ways, on the spot, until I finally was able to wrap my head around the concept and see a dramatic increase in my score. This program is exactly what students need when they try to tackle the LSAT."

"Justin has ironed out a strategic method for mastering this beast of a test that will work for anyone who is serious about attending law school…I learned not only how to strategically and psychologically approach the LSAT but also how to read, think, and write analytically and logically; skills that will benefit me throughout both law school and life."

"I love LSAT Engine and the guidance it provided. The pacing and skills taught were crucial for my success on the LSAT. Justin kept tabs on me and my progress, and it was like having my own success coach guiding me along my LSAT prep path. Furthermore, if anything was wrong or if I wanted additional practice in a certain area, Justin would provide the extra material. I have already recommended the program to numerous friends and will continue to recommend it!"

"I love LSAT Engine and the guidance it provided. The pacing and skills taught were crucial for my success on the LSAT. Justin kept tabs on me and my progress, and it was like having my own success coach guiding me along my LSAT prep path. Furthermore, if anything was wrong or if I wanted additional practice in a certain area, Justin would provide the extra material. I have already recommended the program to numerous friends and will continue to recommend it!"

"LSAT Engine is a great program for individuals who want to work at their own pace. The online platform makes it really easy to work from anywhere and offers great practice for the online LSAT format. The video explanations and practice questions were extremely helpful as I prepared for the LSAT, and I appreciated the structure of the program itself. The layout of the modules was easy to understand and enabled me to see what areas I needed to work on the most. The support the staff offers is fantastic!
My decision to attend law school came fairly late, so I only had 3 months to prepare for the LSAT. I scored 10 points higher on the LSAT than on the first practice test I took cold. LSAT Engine was recommended by my Pre-Law Advisor and was the only prep program I used. I would highly recommend it!"

"I am deeply appreciative of all the help I received from Justin and the LSAT Engine team. Justin was extremely patient and always went out of his way to help. The program is designed flawlessly to help students achieve their best score. I am so grateful I found them."



© 2022 Automatic Test Preparation


